Why Did an AI Flag a Raksha Bandhan Story as Prohibited Content?
Adaptiv Admin
Apr 14, 2026 · 7 min read

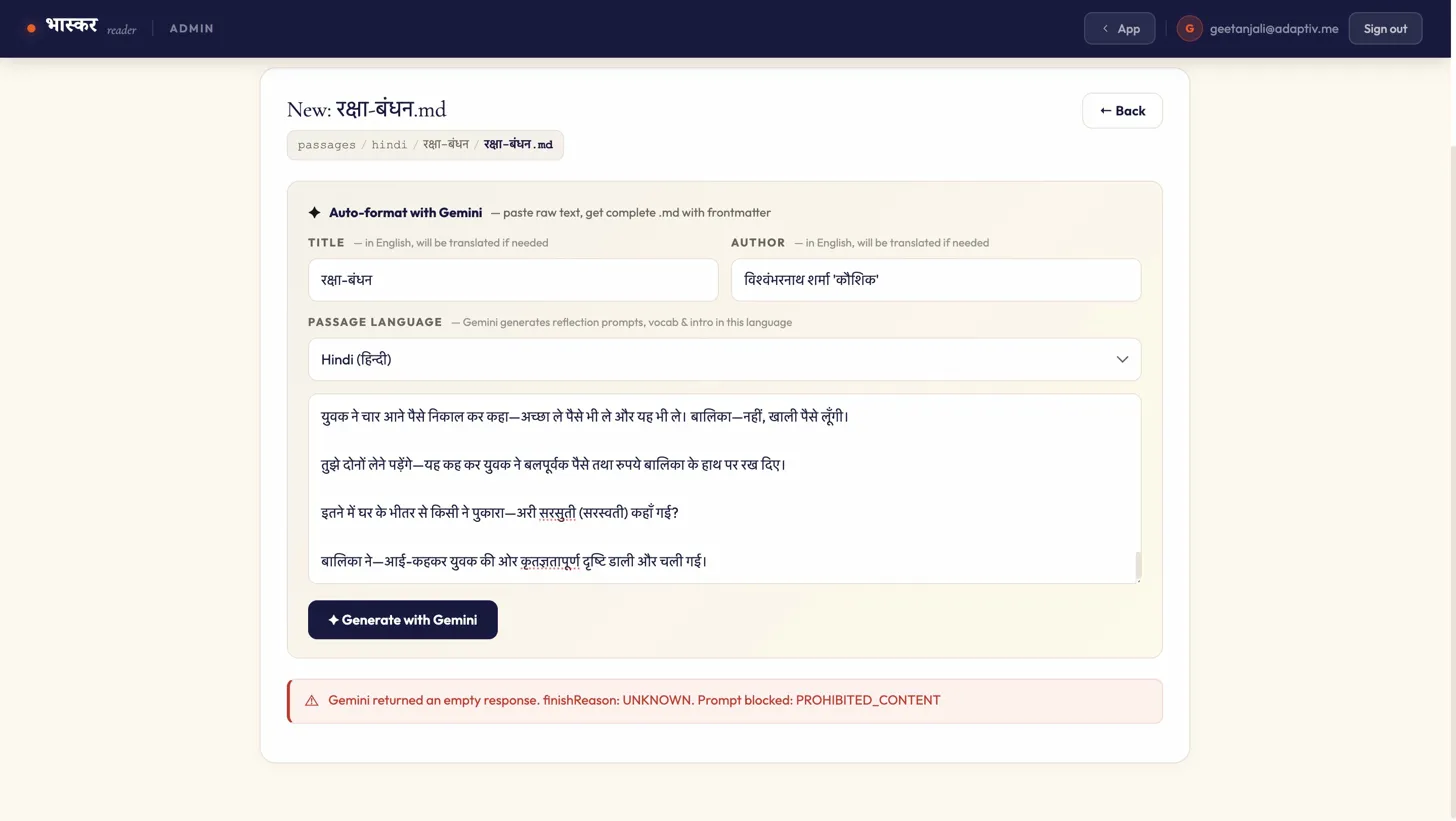
Last week, while adding a Hindi literary passage to Bhaskar Reader, we hit a wall. The passage - an excerpt from रक्षा बंधन by विश्वंभरनाथ शर्मा 'कौशिक' - was blocked outright. AI returned an empty response: finishReason: UNKNOWN. Prompt blocked: PROHIBITED_CONTENT.
No nuance. No partial output. Just a flat refusal to process a text that has been part of Hindi literary curricula for decades. This incident offers a useful lens into a problem that anyone working with Indian language texts and LLMs will eventually encounter:
Current AI moderation systems are not equipped to handle the linguistic and cultural conventions of indigenous literature.
The Context
Bhaskar Reader is an app encourage the discovery and appreciation of literary texts in Indian languages, and rekindle the love of reading among the Indian youth. With this objective in mind, we are curating passages that are then processed and made accessible through various annotation tools and reflection prompts. While ingesting a Hindi passage from a well-known story about Raksha Bandhan, रक्षा बंधन by Vishwambharnath Sharma 'Kaushik', our pipeline raised safety flags. The content was marked for child endangerment, toxicity, and potentially unsafe interaction between an adult and a minor.
To anyone who has read the story, or indeed grown up in a culture where Raksha Bandhan carries deep emotional weight, this is an absurd outcome. But to the AI safety filter, it was entirely logical. And that gap between logical and absurd is precisely the problem we need to talk about.
The Passage and the Flag
The story is straightforward: a young girl wants to celebrate Raksha Bandhan but has no brother to tie a Rakhi to. Her mother, consumed by grief over the deaths of the girl's father and brother, directs her anguish at the child. A stranger on the street recognises the girl's sadness and offers her money to buy a Rakhi, stepping into the role of a surrogate brother - a culturally familiar gesture during the festival.
A deeper analysis of the text in light of known AI moderation rules made us realise that two specific sections almost certainly triggered the block.
1. Idiomatic grief misclassified as abuse. The mother says: "पैदा होते ही बाप को खा बैठी" — literally, "you ate your father the moment you were born." In Hindi, "खा बैठी" is a common idiomatic construction expressing blame or misfortune. No native speaker reads this as literal. But a safety filter scanning for patterns of an adult directing violent or abusive language at a child has no mechanism to distinguish idiom from intent. The phrase maps neatly onto toxicity and child endangerment categories.
2. A keyword collision around a minor. Near the story's end, the text reads: "युवक ने बलपूर्वक पैसे तथा रुपये बालिका के हाथ पर रख दिए" — "the young man forcefully placed the coins in the girl's hand." The word बलपूर्वक (forcefully) co-occurring with युवक (young man) and बालिका (girl) is a textbook trigger for child safety filters. In context, the man is insisting she accept a gift. Out of context, the keyword cluster: adult male, force, female child is exactly what these filters are designed to catch.
The Technical Gap
What happened here is not a mystery. Safety filters in large language models work primarily through pattern recognition: keyword co-occurrence, relationship dynamics between entities (adult/child, male/female), and sentiment scoring. These systems are effective at catching genuinely harmful content at scale. But they operate without access to the layers of meaning that make literary language function - idiom, cultural convention, narrative arc, genre, and authorial intent.
This is a known limitation, but it becomes significantly more pronounced with Indian languages for a few specific reasons.
The training and evaluation data for safety classifiers skews heavily toward English. The taxonomies of harm - what counts as "toxic," what constitutes "unsafe interaction" - are derived largely from English-language content moderation contexts. These categories do not map one-to-one onto Hindi, Tamil, Bangla, or Urdu literary expression.
Indian languages make extensive use of figurative and hyperbolic registers in everyday speech and literature alike. Expressions that are emotionally intense but idiomatically routine - blaming a child for cosmic misfortune, using the language of force to describe insistence - are common across genres. A moderation system calibrated for literal interpretation will generate false positives at a structurally higher rate with these texts.
Culturally specific institutions like Raksha Bandhan - where strangers can become honorary siblings - create relationship dynamics that don't fit neatly into the risk categories these filters use. The interaction between the young man and the girl in this story is not an edge case in Indian culture. It is the entire point of the festival.
If a gentle Raksha Bandhan story triggers a safety flag, what happens when these systems encounter Premchand's portrayal of rural poverty, Ismat Chughtai's explorations of desire, or the raw testimony of a Dalit memoir? Such texts are often suppressed, deprioritised, or marked as unsafe by the accumulated weight of a thousand small algorithmic misreadings.
The result is a slow, invisible erosion. Literary heritage that should be digitised and made accessible is instead filtered out. Researchers and educators working in Indian languages learn to distrust AI tools, or worse, to avoid feeding them the very texts that most need preservation. The promise of AI-assisted access to indigenous literature is undermined by the tools themselves.
The Practical Consequences
For a project like Bhaskar Reader, which processes literary texts in Indian languages to make them accessible for learners and readers, this is not an abstract concern. A PROHIBITED_CONTENT block means the pipeline stops. The passage cannot be auto-formatted, vocabulary cannot be generated, and reflection prompts cannot be created. The text effectively becomes invisible to the system.
Scale this up and the implications are significant. Hindi literature alone contains vast bodies of work dealing with poverty, caste, partition, gender, and communal violence, precisely because literature is how cultures process difficult experience. If moderation filters cannot distinguish between a story about suffering, and content that promotes harm, large portions of Indian literary heritage become systematically harder to digitise, process, and distribute through AI-assisted tools.
Preserving literature means preserving the nuances that give it life.
What Would Help
A few concrete steps would meaningfully reduce false positives for indigenous literary texts without compromising safety objectives.
Culturally informed annotation. Safety training datasets need labelling from annotators who are native readers of the target languages, with literary and cultural competence - not just translation of English-language harm categories.
Context-aware classification. Moving beyond keyword and entity co-occurrence toward models that can assess narrative function. A mother blaming a child in a story about grief is performing a different speech act than the same words in a social media post.
Configurable safety tiers. Literary and academic processing pipelines have different risk profiles than consumer-facing chat applications. Allowing domain-appropriate thresholds, with appropriate safeguard, would prevent culturally significant texts from being blocked wholesale.
Language-specific evaluation benchmarks. False positive rates should be measured per language, per genre. If a safety system blocks 15% of pre-independence Hindi short fiction, that is a data point worth knowing and acting on.
Moving Forward
The error message we encountered Prompt blocked: PROHIBITED_CONTENT is definitive in a way that the underlying situation is not. The content is not prohibited. It is a story about compassion, published decades ago, read by schoolchildren across India. If you are building or evaluating safety classifiers for multilingual content, start measuring false positive rates across languages and genres. The data will speak for itself.
Adaptiv Admin
@admin
Building the future of AI products at Adaptiv.Me.




